The bacterium Esherichia coli is the most thoroughly studied one-celled organism in the world. How complex is it? What was needed, to think it out and to make it? How long is its genome (DNA-chain)? How much protein and tRNA do its ribosomes, its protein factories, contain? And how complex are its enzymes?
It might well be that you, dear reader, do not understand some or even most of the technical details. But do not worry about it. Even the foremost microbiologists of the world still do know only a little bit about it. Much of it they have not understood yet at all. This will show you the more, how much the tiny cell knows about science. And you may ask yourself then: Why does this bacterium know all of these things about physics, chemistry, and microbiology?
Frederic C. Neidhardt, University of Michigan, Ann Arbor, John L. Ingraham, University of California Davis, and Moselio Schaechter, Tufts University, Boston, state in their textbook Physiology of the Bacterial Cell (1990:14):
"The complete, single chromosome of E. coli is known, with considerable precision, to be a circular, covalently closed, double-stranded molecule of 4,720,000 base pairs (4,720 kilobase pairs or kbp for short). Therefore its molecular weight is about 2.5·109, and stretched out, it is approximately 1 mm long. How such a structure is arranged within a cell that is only 1/500th its length is an interesting story.
"What can 4,720 kbp do for a cell? Recall that the average molecular weight of E. coli proteins is 40,000 and the average molecular weight of an amino acid residue in protein is 110. Therefore the average protein has 364 amino acids. Because it takes three nucleotide bases in DNA to specify each amino acid residue in a protein, the average gene size in E. coli is approximately 1.1 kbp... Reasonable corrections for of DNA that does not encode protein lead to a 'best guess' of 3,800 possible protein-encoding genes."
Frederick R. Blattner and co-workers have studied the complete genome sequence of Escherichia coli K-12. They report about their findings in Science, vol. 277, 5 September 1997, p. 1453: Escherichia coli K-12 has a genome length of 4,639,221 base pairs. Escherichia coli is an important component of the biosphere. It colonizes the lower gut of animals. And as a facultative anaerobe, survives when released to the natural environment, allowing widespread dissemination to new hosts. How much information is needed, to put the base pairs of this DNA-chain into the right place?
4,639,221 bp log 4 = 102,793,089 bit. So much information is needed, to put the base pairs of its DNA-chain into the right place.
What have scientists found out now about the ribosome of the bacterium E. coli? Why is it there? How does it work? And how complex is it?
James D. Watson and co-workers: "Once the amino acids have acquired their adapters, they diffuse to the ribosomes, which might be regarded as miniature factories for making proteins. Their chief function is to orient the incoming AA-tRNA precursor and the template RNA so that the genetic code can be read accurately. Ribosomes thus contain specific surfaces that bind the template RNA, the AA-tRNA precursors, and the growing polypeptide chain in suitable stereochemical positions.
"There are approximately 15,000 ribosomes in a rapidly growing E. coli cell. Each ribosome has a molecular weight of slightly less than 3 million daltons. Together the ribosomes account for about one-fourth the total bacterial cell mass, and hence a very sizable fraction of the total cellular synthesis is devoted to the task of making ribosomes. Only one polypeptide chain can be formed at a time on a single ribosome. Under optimal conditions, the production of a chain of 400 amino acids (molecular weight of about 40,000) requires about 10 seconds. The finished polypeptide chain is then released, and the free ribosome can be used immediately to make another protein.
"All ribosomes are constructed from two subunits, the larger subunit being approximately twice the size of the smaller one. Both subunits contain both RNA and protein. In bacterial ribosomes, the RNA: protein ratio is about 2:1; in many other organisms, it is about 1:1. Both the large and small subunits contain a large number of different proteins. Intensive work has been done with the ribosomal proteins from E. coli.
"The 21S proteins (labeled S1 to S21) from the smaller (30SI) subunit show a variety of sizes. Recently, all have been sequenced, and it has become clear that each is present in only one copy per ribosome. Likewise, of the 34L proteins (L1 toL34) in the larger (50S) subunit, most are present only once in a given ribosome."
"In general, the size of the protein decreases with increasing numbers. That is S1 is the largest protein (MW about 60,000) and S21 is the smallest protein (MW about 8000) on the 30S ribosome, and L1 is the largest protein (MW about 25,000) and L34 the smallest protein (MW about 5000) on the 50S ribosome." Watson J. D. et al. (1987:393, 394). - MW = molecular weight.
The RNA in the ribosome comes in three basic sizes. How large are these chains? And how many nucleotides do they have?
James D. Watson and co-workers: "Two large tRNA molecules and one small tRNA molecule are found in every bacterial ribosome. They are integral components, and unlike mRNA, cannot be removed without the complete collapse of the ribosome structure. The 16S rRNA molecule, found in the smaller ribosomal subunit, has a chain length of 1542 nucleotides, whereas the 23S molecule, a component of the larger ribosomal subunit, contains 2904 nucleotides. Each larger subunit contains, in addition, one very short rRNA molecule that sediments at 5S and has 120 nucleotides. All three tRNAs are single-stranded and have unequal amounts of guanine and cytosine and of adenine and uracil.
"Despite of these RNA-RNA interactions we are still very far from understanding what the hundreds of unpaired nucleotides of each rRNA component are doing. ... The 16S, 23S, and 5S rRNAs are transcribed in that order into a single 30S pre-tRNA transcript of about 6500 nucleotides. ... In the case of the pre-rRNA, it is clearly advantageous to include 16S, and 5S sequences in a single transcript to ensure that equivalent numbers of the three molecules will be available for ribosome assembly." (1987:395-400).
What is messenger RNA? What is it doing in the cell? And how complex is it?
James D. Watson and co-workers: "This RNA reversibly binds to the surface of the smaller ribosomal subunit... Because it carries the genetic message from the gene to the ribosomal factories, this particular kind of RNA is called messenger RNA (mRNA). By moving across the ribosomal site of protein synthesis, mRNA brings successive codons into position to select the appropriate AA-rRNA precursors. ...
"In contrast to tRNA molecules, which have molecular weights of about 2.5 x 104, and to rRNA molelcules, which also have defined sizes (4 x 104, 5 x 105, and 106 for 5S, 16S, and 23S, respectively), mRNA molecules vary greatly in chain length and hence in molecular weight. ... Most polypeptide chains contain 100 or more amino acids, and so most mRNA molecules must contain at least 100 x 3 nucleotides (because there are three nucleotides in a codon). ... In E. coli, therefore, the mRNAs that code for average-size polypeptides of 300 to 500 amino acids usually contain between 1000 and 2000 nucleotides.
"For example, a single mRNA molecule codes for the five specific enzymes needed to synthesize the amino acid tryptophan. It has recently been completely sequenced and contains about 6800 nucleotides, or an average of 1400 nucleotides coding for each enzyme and its adjacent intergenic regions." (1987:395, 404, 406).
"Most is known about an enzyme called ribonuclease P (PNase P), which removes the extra 5´ nucleotides. ... Purification of Rnase P led to the realization that the enzyme is not a pure protein. Rather, it is a noncovalent complex of a small RNA molecule 377 residues long) and a small protein (MW about 20,000). Reconstitution studies, as well as the identification of mutants in RNA and in the protein, have shown that both components contribute to Rnase P activity under physiological conditions." Watson, J. D. et al. (1987:402).
How much information does a bacterial cell contain, like Escherichia coli, for example? In other words: What was needed, to think it out and to make it? The chains of DNA, RNA and protein in the cell are like the written text in a book, with its letters, sentences, and chapters. Let us take a simple sentence from a telegram, as an example:
I HAVE RECEIVED NOW THE BOOKS
How much information does this sentence contain? The English language, with an alphabet of 27 signs (26 letters and 1 empty space) has 4.05 bit/letter (Gitt, W. 1986:64). This sentence has 24 letters and 5 space bars: 29 signs in an alphabet of 27 signs. 29 x 4.05 bit/letter = 117.45 bit of statistical information. - How much statistical information will this sentence have, if we mix them all up?
WERHA VOIN EKN VBEOC IESD OTE
The sentence, with its 29 signs, still contains a statistical information of 117.45 bit. But it does not mean anything anymore. So we must ask ourselves now: How much information is needed, to put the 29 signs of this sentence into the right order? In other words: What are its sequence alternatives? - 29 signs log 27 = 41.5 = 1041. This means: 1041 yes/no decisions (or sequence alternatives) we need now, to put these 29 signs into the right order. 1041 yes/no decisions are 1041 bit of information. What does that mean? How much information is that?
All of man's knowledge, written down now in books, contains 1018 bit of information. 1041 : 1018 = 1·1023. This means: The information, which is contained in the sequence alternatives of this simple sentence, is 1023 times larger, than all of mankind's knowledge, written down now in books. This will help us, to find out, if life on earth could have evolved by itself from inorganic matter of the "chemical soup".
Escherichia coli, Yes/No Decisions
What are the yes/no decisions of the DNA, RNA, and protein chains in the bacterial cell Escherichia coli? What are their sequence alternatives? How much information was needed, to put them into the right order? This will also help us, to find out, if the so-called "16S-rRNA phylogenetic tree" is science or only science fiction.
The genome (DNA-chain) of E. coli has 4 720 000 base pairs. The DNA-code has 4 letters (nucleotides). And it takes 3 nucleotide bases of DNA to specify each amino acid residue in a protein (Neidhardt, F. D. et al., 1990:14). 4 720 000 bp DNA log 4 = 102 841 723 bit.
Most of the genetic information of the bacterial cell is encoded (written down and stored) on its genome (DNA-chain). Thus, 102 841 723 bit information is needed, to put these 4 720 000 DNA letters into the right order. All of mankind's knowledge, written down no in books, is only 1018 bit!
One must be a trained microbiologist or molecular biologist, in order to understand the cell's genome (a little), and to work with it. But no scientist has ever been able to make the whole DNA chain (genome) of Escherichia coli, because it is far too complicated. So, the person, thinks out and makes the whole living cell, with its genome, must know much more, than a highly qualified human microbiologist. An ape cannot work as a microbiologist. It knows too little.
The human genome has about 3 500 000 000 base pairs. How much information was needed, to put them into the right order? 3 500 000 000 bp log 4 = 102 107 209 970 bit.
This means: The human genome, with its 3.5 billion base pairs, has at least 102 107 209 970 bit of information or yes/no decisions. An intelligent person first had to think out and to make this genetic information: God.
The 16S rRNA phylogenetic tree of life is supposed to prove that all life on earth has evolved from a common ancestor, from the first primitive cell. And this first primitive cell is supposed to have evolved by itself in the primordial "chemical soup" from inorganic matter. There are three different types of rRNA chains in the bacterial ribosome: 16S, 23S, and 5S. These ribosomal RNA chains are single stranded. And they are interwoven with the ribosome's proteins. There are 21 different types of protein (S1-S21) in the small subunit of the ribosome, and 34 proteins in the large subunit of the ribosome (L1-L34). - How large are they? And how much information do they contain? How have they come into being?
16S rRNA. The 16S rRNA molecule is a chain of 1542 nucleotides. How much information was needed to put them into the right order? 1542 rRNA nucleotides log 4 = 10928 bit.
This means: It took at least 10928 bit of information (yes/no decisions), to make the 16S rRNA molecule of the bacterium E. coli.
23S rRNA. The 23S rRNA molecule has 2904 nucleotides. At least 101748 yes/no decisions (or bit of information) were needed, to make it.
5S rRNA. The 5S rRNA molecule has 120 nucleotides. It took 1072 yes/no decisions (or bit of information), to make it.
"16S, 23S and 5S rRNAs are transcribed in that order into a single 30S pre-rRNA transcript of about 6500 nucleotides", report James D. Watson and co-workers (1987:400). In this way, the 3 molecules will be made in the same amount. - What was needed, to make this combined chain of 6500 rRNA nucleotides? It has 103913 sequence alternatives or bit of information. This clearly disproves the belief in the 16S rRNA phylogenetic tree of life that all life on earth has evolved from the first primitive ancestral cell. That is only science fiction.
The largest protein on the 30S ribosome, S1, has a molecular weight of 60 000. - How many amino acids are that? How much information was needed, to put them into the right order? And how much DNA was needed to make this protein?
1 amino acid has a molecular weight of 110. Thus, 60 000 MW : 110 MW = 545 amino acids. 545 log 20 = 10709. The protein code has an alphabet of 20 letters (amino acids). Three specific nucleotides are needed, to make 1 amino acid. 545 x 3 = 1635 nucleotides. 1635 nucleotides log 4 = 10984. We add up now these two sequence alternatives 10709 and 10984 and get 101693. This means: At least 101693 bit of information were needed, to make the largest protein S1 in the 30S ribosome. And in the whole bacterial ribosome there are 55 different proteins.
Soluble Factors in E. coli. Also certain soluble factors are involved in E. coli, when making different parts of the cell from its genetic information. These are proteins, needed for initiation, elongation, and termination. How large are these proteins? - J. D. Watson et al. (1987:413) give the following values:
IF1 9000 MW, IF2 120 000 MW, IF3 22 000 MW.
Elongation: EF-Tu 45 000 MW, EF-Ts 30 000 MW, EF-G 80 000 MW.
Termination: RF1 36 000 MW, RF2 38 000 MW, RF3 46 000 MW.
Let us look now briefly at just one example, at the IF2, the protein for initiation, with its molecular weight of 120 000. How many amino acids are needed, to make it? And how much information was needed, to put these amino acids into the right order? How much DNA was needed, to make this protein IF2? And what was needed, to put the nucleotides of this DNA chain into the right order, so that it text becomes meaningful and serves its purpose?
Initiation-Protein IF2. The initiation protein IF2 of E. coli has a molecular weight of 120 000. One amino acid has a molecular weight of 110. Thus, there are 1090 amino acids. 1090 amino acids log 20 = 101419. - 1090 amino acids x 3 nucleotides/1 amino acid = 4257 nucleotides. 4257 log 4 = 102563. When adding these two sequence alternatives, we get a total of 103982. This means: It took at least 103982 bit of information (yes/no decisions), to make the initiation protein IF2 of the bacterial cell E. coli, with its molecular weight of 120 000.
Transfer RNA. How complex is a transport RNA Molecule (tRNA) in E. coli? How large is it? - The tRNA molecule has a molecular weight of 2.5·104, according to Watson, J. D. et al. (1987:404). One base of DNA or RNA (1 nucleotide) has a molecular weight of 330 MW: half as much as the molecular weight of one base pair, which is 660 MW, as reported by Arthur Kronberg and Tania A. Baker (1992:20) and Christian de Duve (1986).
2.5·104 MW : 330 MW = 75.75 RNA nuclelotides.
75 RNA nucleotides log 4 = 1045.
This means: 1045 bit of information is needed, to make one tRNA molecule.
Messenger RNA. A single mRNA molecule encodes for 5 specific enzymes, which are needed to synthesize the amino acid tryptophan. It has 6800 nucleotides. There are 1400 nucleotides for each enzyme and its adjacent intergenic regions, according to J. D. Watson et al. (1987:406). What was needed, then, to make this mRNA molecule?
6800 nucleotides log 4 = 109 094. And each one of the 5 specific enzymes, with 1400 nucleotides each, has 10842 bit information or yes/no decisions. This proves creation, and disproves evolution. Information and mathematics always have their source in the spiritual, non-material world, in the mind of an intelligent being: the Creator.
How does the living cell duplicate itself? And how accurately does it duplicate its DNA?
Morislav Radman is a research director at the National Center for Scientific Research (CNRS) in Paris. The American Robert Wagner has worked there together with him. They report in their article "The High Fidelity of DNA Duplication" in Scientific American, August 1988 page 24:
"All of life depends on the accurate transmission of information. As genetic messages are passed along through generations of dividing cells, even small mistakes can be life threatening. In human beings the substitution of a single 'letter' in the genetic message is responsible for such lethal hereditary diseases as sickle-cell anemia and thalassemia. Several common cancers are also associated with a single-letter change.
"For organisms as complex as human beings, attaining sufficient accuracy is a monumental feat. The set of genetic instructions for humans is roughly three billion letters long. If mistakes were as rare as one in a million, 3,000 mistakes would be made during each duplication of the human genome. Since the genome replicates about a million billion times in the course of building a human being from a single fertilized egg, it is unlikely that the human organism could tolerate such a high rate of error. In fact, the actual rate of mistakes is more like one in 10 billion. How do cells achieve such high fidelity?
"In the cells of all living organisms the genetic message is contained in double-stranded DNA. DNA's structure is marvelously suited to maintaining the integrity of the genetic message. The two strands are complementary, which is to say they carry the same genetic information, in the sense that positive and negative strips of movie film portray the same scene. Like the strips of film, one strand of DNA can be used to reconstruct the other. If the one strand is damaged, it can be repaired by removing the undamaged strand as a template for synthesizing a new strand. Indeed, DNA is routinely replicated by a similar process: the two parent strands are separated at a 'replication fork,' and each becomes a template for building a new strand." Radman, M. and R. Wagner (1988:24).
"The biochemical 'letters' that encode information in DNA are four nucleotides, which are distinguished by the bases they contain. The bases are adenine, guanine, thymine and cytosine, commonly designated A, G, T and C. The order in which nucleotides occur determines the 'meaning' of the genetic message. The bases on one strand pair with the bases on the other strand, linking the two strands like rungs on a ladder. The pairing is not random: adenine must pair with thymine, and guanine must pair with cytosine. Hence the complementarity of base pairs is the bases for the complementarity of DNA strands." (1988:25, 26).
When can errors in DNA-duplication arise?
M. Radman and R. Wagner (who believe in evolution), state: "Errors arising in the course of DNA synthesis can result in noncomplementary base pairs, or mismatches. Other kinds of errors can be introduced by environmental influences. Repair of environmental damage from DNA (from chemicals, radiation and so on)... When DNA is synthesized in the absence of enzymes, such errors happen about once in every 100 bases. The enzymatic systems discussed here make synthesis 100 million times more accurate than nonenzymatic synthesis." (1988:26).
Why is the cell duplicating its genetic information, its DNA, so accurate?
H. Radman and R. Wagner: "Three enzymatic processes are responsible for the high fidelity of DNA replication. The first process is involved in selecting which of the four nucleotides is added to the nascent (= free) strand. The second process involves 'proofreading' the most recently added nucleotide and expelling it if it is noncomplementary. The third process takes place after synthesis and involves correcting errors that escaped the first two 'editors.' Because nucleotide selection and proofreading act in concert with the DNA replication machinery, they are known as error-avoidance mechanisms. The mechanism that operates after synthesis is an error-correction mechanism; it is called mismatch repair.
"The accuracy of replication is due primarily to the effectiveness of nucleotide selection. The selection is mediated by the same enzyme that carries out the polymerization of nucleotides. The enzyme, called DNA polymerase, moves along the DNA template and synthesizes the complementary strand from the cellular pool of nucleotides. The free nucleotides are in the form of triphosphates that is, they carry a string of three phosphate groups. The nucleotides must be cleaved to monophosphates before they can be added to the new strand. DNA polymerase takes up a nucleotide triphosphate, cleaves it to a monophasphate and adds the latter to the end of the nascent (= free) strand." Radman, M. and R. Wagner (1988:26).
"Nucleotide selection depends on the energetic relations between competing reactions; in other words, it is possible to insert any base opposite any other base, but the correct pairing is the most energetically favorable. ... If a nucleotide is indeed complementary, it fits well with the template base and the addition is stabilized. If the nucleotide is noncomplementary, it does not fit well, the reaction is reversed and the nucleotide is restored to its triphosphate form. An apt metaphorical role for the polymerase would be that of a blind cook, who grabs ingredients at random, tastes each one and decides whether to add it to the soup or put it back on the shelf.
"At the level of nucleotide selection, noncomplementary nucleotides are incorporated at a rate of about one in 100,000. An error that slips through this process encounters the second mechanism or error avoidance: proof-reading. Proofreading is carried out by an enzymatic activity that is either part of or associated with the DNA polymerase. This activity was nicknamed 'proofreading exonuclease'... The exonuclease is capable of removing both complementary and noncomplementary nucleotides from the terminal of the nascent chain. However, as a rule it only gets the opportunity to act when a nucleotide is noncomplementary. The presence of the mismatched nucleotide greatly inhibits the addition of the next nucleotide, and the pause in the polymerization process gives the exonuclease time to remove the noncomplementary nucleotide. The polymerase then tries again to find a complementary nucleotide for the terminal position.
"Under ordinary circumstances the combination of nucleotide selection and proofreading by exonuclease results in an error rate of about one mistake per 10 million base pairs. But both error-avoidance mechanisms can be impaired if the pool of triphosphates that supplies the raw material for synthesis has unequal proportions of the four kinds of nucleotides." Radman, M. and R. Wagner (1988:26, 27).
"Error-avoidance mechanisms are straightforward enzymatic reactions in which more energetically desirable outcomes prevail over less stable outcomes. Error correction is a little more complicated. In order to correct a mismatch in newly synthesized DNA, the enzymatic machinery must be able to detect and remove a mismatched nucleotide, and to regenerate the correct sequence.
"Most of what is known about high-fidelity mechanisms of DNA replication comes from experiments with bacteria. To what extent can this knowledge be applied to more complex organisms? Both error-avoidance mechanisms are probably common to almost all organisms, where they would operate in essentially the same way. There is also ample evidence that mismatch repair occurs in yeast, fungi and fruit flies, as well as in frogs and mammals.
"However, most of the evidence pertains to errors arising not during replication but rather in the course of genetic recombination, in which strands of DNA are swapped between molecules of different parentage." Radman, M. and R. Wagner (1988.29).
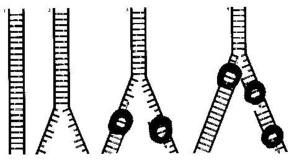
Replication fork divides the double-stranded DNA molecule (1) like a zipper (2). Synthesizing enzymes called DNA polymerases attach to the bared parental strand, and synthesis of the two nascent strands (arising, getting free) proceeds in opposite directions (3). The polymerase on one side tags along the advancing fork. On the other side new polymerases must keep binding close to the fork to synthesize the strand between the fork and the site at which the last polymerase bound (4). After M. Radman et al. (1988:26).
![]()
Proofreading is done by an exonuclease activity that is associated with the polymerase. Exonuclease removes nucleotides that have been added to the strand. When a mismatch at the terminal base pair shows the incorporation of the subsequent nucleotide (1), the exonuclease (an enzyme) has time to act (2). The polymerase then repeats its search for the proper match (3). From M. Radman et al. (1988:28). When DNA is synthesized (= is made) in the absence of enzymes, errors happen about once in every 100 base pairs. With enzymes, synthesis is 100 million times more accurate, than without enzymes. There is then only 1 mistake in 10 billion (= 10,000 million) bases.
The living cell has a genetic code and a translating apparatus. Why do they exist? Why have they arisen? And why does a certain nucleotide code word (DNA triplet) mean something? How are DNA-code and protein code physically connected?
James Darnell, Rockefeller University, Harvey Lodish, Massachusetts Institute of Technology, and David Baltimore, Rockefeller University, all believe in evolution. But they do admit in their textbook Molecular Cell Biology (1990:1131) under the heading "The Origins of the Genetic Code and the Translating Apparatus":
"During precellular evolution two different but coordinated problems had to be solved to enable nucleic acids to store information that could specify proteins. First, a correspondence had to be established between a linear order in one polymer and a linear order in the other - that is, a code had to develop; second, a means of translating the one linear order into the other had to be found. We know that in all cells the present-day three-latter nucleotide code in mRNA fulfills the first of these requirements and that the translation function is carried out by tRNA bound to the ribosome. However, the mechanism by which the nucleotide code 'words' were chosen may always remain speculative, because there is no known chemical complementarity between the three nucleotides of a codon and its cognate amino acid."
"A detailed theory of evolution that would explain how the primitive oligonucleotide-oligopeptide interactions developed into a working translation system is entirely beyond the limits of present knowledge. ... We indicated earlier that absolute conclusions about the nature of the earliest genes or the earliest cells may never be possible." Darnell, J. et al. (1990:1056, 1071).
Evolutionists have tried to get out of their difficulties by saying: The first cell on earth arose from an RNA-molecule in the primordial chemical soup. - Is that true? Is that scientific?
Robert Shapiro is Professor of Chemistry at the University of New York, U.S.A. He reports: "The discovery of catalytic ability in RNA has given fresh impetus to speculations that RNA played a critical role in the origin of life. This question must rest on the plausibility of prebiotic oligonucleotide synthesis, rather than on the properties of the final product. Many claims have been published to support the idea that the components of RNA were readily available on the prebiotic earth. ... The evidence that is currently available does not support the availability of ribose on the prebiotic earth, except perhaps for brief periods of time, in low concentration as part of a complex mixture, and under conditions unsuitable for nucleoside synthesis.
"It has been suggested that 'life began with an RNA world' (Gilbert, 1986), containing only replicating RNA species and ribonucleotides (Sharp, 1985). According to Gilbert: 'The first stage of evolution proceeds, then, by RNA molecules performing the catalytic activities necessary to assembling from a nucleoside soup'." (1988:71).
"Many scientists and writers concerned with the origin of life have assumed that the necessary parts for RNA construction were readily available on the prebiotic Earth. For example, Eigen and Schuster (1978) stated 'Here we simply start from the assumption that when self-organization began, all kinds of energy-rich material were ubiquitous (= everywhere), including in particular: amino acids in varying degrees of abundance, nucleotides involving the four bases, A, U, C, G, polymers of both preceding classes... having more or less random sequences.' The same authors wrote at a later date (Eigen and Schuster, 1982): 'The building blocks of polynucleotides - the four bases, ribose and phosphate form steadily refilling pools for the formation of polymers, among them polypeptides and polynucleotides'. Kuhn and Waser (1981) wrote in a similar mode: 'The most important components of our model for the origin and the earliest steps of life are amino acids, ribose, and the nucleotide bases G, C, A, and U. These substances were presumably abundant on the primordial planet and might have accumulated in particular regions by natural concentration processes, such as evaporation of an aqueous solution and redissolution of the residue, or by adsorptions and desorptions.'
"Conclusions: The evidence that is currently available does not support the availability of ribose on the prebiotic earth, except perhaps for brief periods of time, in low concentration, as part of a complex mixture, under circumstances that are unsuitable for nucleoside synthesis. ... In the interim, one other possibility deserves serious consideration: that RNA was not present at the start of life, but was first produced by biosynthetic processes..." Shapiro, R. (1988:73, 74).
How complex is the bacterial cell? How much about it does one know now?
James D. Watson, together with Francis Crick and Maurice Wilkins, were awarded the Nobel Prize in 1962. He is working now at the Cold Spring Harbor Laboratory. James D. Watson and his co-workers state in their textbook Molecular Biology of the Gene, under the heading: "Even small cells are very complex": "Thus, we must immediately admit that the structure of a cell will never be understood in the same way that we understand water or glucose molecules. Not only will the three-dimensional structures of most cellular proteins remain unsolved, but their location within cells often remains imprecisely defined." (1987:1019).
And under the heading "Bacterial cell: a precisionally fine-tuned machine" they write: "The day has long passed when the question should be asked whether there is more than the laws of chemistry behind the functioning of the bacterial cell. We now see the bacterium as an extraordinarily sophisticated set of interrelated molecules that harmoniously work together in highly predictable ways to ensure the growth and selective survival of more of its kinds. At the heart of these remarkable, almost clockwork-type, machines are the DNA molecules that encode, with total precision, sets of commands that bring into action molecules needed to cope with ever-changing nutritional potentials. ... Exactly how each of the 20 amino acids came to be paired with its codon(s) remains a matter of speculation." Watson, J. D. et al. (1989:122, 123, 459).
Bernd-Olaf Küppers
How complicated are a simple bacterium cell and the cell of a human being? How much genetic information do they contain? What was needed, to think them out and to make them? What do they need, to function? - Bernd-Olaf Küppers is scientific assistant at the Max-Planck-Institute for biophysical Chemistry in Göttingen, West Germany. Nobel-Prize winner Manfred Eigen is the Director of this institute. Küppers’ main-field of research is the origin of life.
Bernd-Olaf Küppers, an evolutionist, writes: “Even a ‘simple’ bacterium-cell is in its material structure immensely complex. ... Its inner life is like a full-automatic chemical factory, where smaller molecules are continuously being built. Hereby, every reaction-step is minutely controlled with the only goal, of keeping the system reproductive.” (1978)
How much information does the bacterium-cell contain? How much, the cell of a man?
O.-B. Küppers: “The genetic information of a bacterium ... contains about four million symbols, that of a man, over one billion. Expressed in our language, the construction plan of a bacterium would have a volume of a book, 1000 pages thick. The construction plan of a human being, already the volume of a library, containing 1000 books. The reproduction of a bacterium normally lasts 20 minutes. Within this time, its construction plan must be transcribed symbol by symbol. And the instruction, encoded therein for the construction of a new bacterium-cell, must be realized.”
Who reads the construction-plan? And who carries out the synthesis-instructions?
B.-O. Küppers: “The analysis of living systems has shown us, that for this again a uniform class of biological macro molecules is responsible: the proteins. They are the function-carriers of living systems. In the form of highly specialized molecular machines, they fulfill all vital tasks, like matter-construction, metabolism, synthesis, and control. Especially among the proteins, there are molecular copying machines, that copy the genetic construction-plan exactly, symbol by symbol.”
This shows us: Even the simplest bacterium-cell is a full-automatic chemical factory. Its genetic information, expressed in our language, would fill a book, 1000 pages thick. It reads and transcribes all of its genetic information, and builds a new bacterium-cell from it, within only 20 minutes! - Here we must ask ourselves: Could all that have come into being through a “glass-pearl game of chance”, or through a dialectic struggle, a qualitative change of matter?
Evolutionist B.-O. Küppers: “The likelihood of a chance-synthesis of a ‘primordial gene’ is obviously reversibly proportional to the number of its sequence-number-alternatives, that can be combined. In the simple case of the bacterium-cell, this number is already 102 000 000. That is a 1 with two million zeros! Thus, it is absolutely unlikely that in a molecular roulette-game, the construction plan of even the simplest cell could evolve. It would be just as likely to get a complete textbook of biology, by just mixing the letters.” (1978).
We have found out now: The “inner life” of a “simple” bacterium cell is “immensely complex”, like a “full-automatic factory”. “Every reaction-step is minutely controlled” there. The genetic information of a bacterium contains about 4,000,000 molecular symbols. Expressed in the language of man, the bacterium’s genetic information would fill a book, 1000 pages thick. All of this information is reproduced within 20 minutes, symbol by symbol, when a new bacterium cell is made.
Does an automatic chemical factory arise by itself through chance mutation and selection? Or through a glass-pearl game of chance? Through natural laws? Or through a dialectic struggle? Does the text of a 1000-page book arise like that? - Hardly. - First, skilled chemical scientists and engineers must think out and build the automatic chemical factory. A person first writes the book. The letters, words, sentences, and chapters did not get in there through a glass-pearl game of chance, through natural laws, or through a qualitative change in a dialectic struggle. That is only wishful thinking, not serious science.
Some do earnestly believe that the virus is the missing link between inorganic matter and the first bacterial cell. - Is that true? Is that scientific?
Jim Brooks, British biochemist, writes about the virus: "Viruses are not self-sustaining organisms; they cannot be considered as living. They are not primitive, but highly sophisticated parasites on cells. ... Viruses have often been thought of as at the threshold of life. But they are apparently not the product of chemical evolution from simpler structures. They are either cells gone wrong or a degenerate product of a higher form of life." (1985:96).
The atoms, which make up the four different types of nucleic acids, with their specific three-dimensional shape, do not know anything about DNA-chains in the living cell. And the atoms in each one of the 20 amino acids, the letters of the protein code, do not know anything about the different proteins in the living cell. And the triplet of the nucleic acid code and the amino acids of the protein code are not connected physically at all. - Why? - Because their meaning is spiritual, non-material.
Information cannot arise by itself, through chance. Nor will information arise accidentally, when 1000 apes are writing on a typewriter for millions of years. The Shakespeare-sonnet, written accidentally by apes, is no information at all, even though it might appear to the reader like the original. For the neo-Darwinian this is the only type of information, which exists in the world.
All the basic teachings of evolution have now been thoroughly disproved. They have nothing to do whatsoever with serious natural science. The evolution hypothesis, as now commonly taught throughout the world, is only a pious myth, an ancient religious belief, dressed up in the white cloak of modern science. The old Sumero-Babylonians believed already that life on earth has evolved from the mud of the Euphrates and Tigris. They believed in chemical evolution already some 4000 years ago. And the old Egyptians believed that life on earth has arisen from the water and mud of their river Nile. - Information, design, planning, purpose, and mathematics, contained in the living cell, do prove that it has been thought out and made by an intelligent Being, by the Creator.